



robots.txt یک فایل متنی است که وب مسترها برای آموزش ربات های وب (معمولاً ربات های موتور جستجو) نحوه Crawl صفحات در وب سایت خود ایجاد می کنند. فایل robots.txt بخشی از (robots exclusion protocol (REP است، گروهی از استانداردهای وب که چگونگی خزیدن ربات ها به وب، دسترسی و فهرست بندی مطالب را تنظیم می کنند و آن محتوا را در اختیار کاربران قرار می دهند. REP همچنین شامل راهنما هایی مانند ربات های متا، و همچنین دستورالعمل های صفحه، فرعی یا راهنمای سایت برای نحوه برخورد موتورهای جستجو با پیوندها (مانند “follow” یا “nofollow”) است. ما در ادامه به شما همراهان عزیز فایل robots.txt چیست را آموزش می دهیم.
فایل robots.txt چیست و چه کاربردی دارد:
در عمل ، فایل های robots.txt نشان می دهند که آیا برخی از کاربران کاربر (نرم افزار crawling وب) می توانند یا نمی توانند قسمت هایی از یک وب سایت را crawl کنند. این دستورالعمل های خزیدن با “مجاز نبودن” یا “مجاز” کردن رفتار برخی از عوامل کاربر (یا همه) کاربر مشخص می شوند.
قالب اصلی:
User-agent: [user-agent name] Disallow: [URL string not to be crawled]
به طور کلی ، این دو خط یک پرونده کامل robots.txt به حساب می آیند – هرچند که یک پرونده ربات می تواند حاوی چندین خط از عوامل و دستورالعمل های کاربر باشد (به عنوان مثال، اجازه نمی دهد، اجازه می دهد، تاخیر در خزیدن و غیره). در یک فایل robots.txt، هر مجموعه از دستورالعمل های کاربر به صورت یک مجموعه گسسته، با یک خط جدا از هم ظاهر می شوند. Msnbot ، discobot و Slurp همه به طور اختصاصی فراخوانی می شوند، بنابراین آن دسته از عوامل کاربر فقط در بخش های فایل robots.txt به دستورالعمل ها توجه می کنند. سایر نمایندگان دستورالعمل های موجود در کاربر را دنبال می کنند.

برخی از چیزهایی که باید درباره Robots.txt بدانید:
- برای یافتن، یک فایل robots.txt باید در فهرست بالای وب سایت قرار بگیرد.
- Robots.txt حساس به حروف بزرگ و کوچک است: پرونده باید “robots.txt” نامگذاری شود (نه Robots.txt ، robots.TXT یا موارد دیگر).
- برخی از نمایندگان کاربر (ربات ها) ممکن است پرونده robots.txt شما را نادیده بگیرند. این امر به ویژه در مورد crawl شدن مبهم تر مانند ربات های مخرب یا اسکنرهای آدرس ایمیل رایج است.
- پرونده /robots.txt در دسترس عموم است: کافی است /robots.txt/ را به انتهای هر دامنه اصلی اضافه کنید تا دستورالعمل های این وب سایت را مشاهده کنید (اگر این سایت پرونده robots.txt دارد!). این بدان معنی است که هر کسی می تواند ببیند صفحات شما چه کاری انجام می دهید یا نمی خواهید خزنده شوند، بنابراین از آنها برای مخفی کردن اطلاعات کاربر خصوصی استفاده نکنید.
- هر زیر دامنه در یک دامنه root از پرونده های جداگانه robots.txt استفاده می کند. این بدان معنی است که هر دو blog.example.com و shembull.com باید پرونده های robots.txt خود را داشته باشند (در blog.example.com/robots.txt و مثال /com./robots.txt).
- به طور کلی بهترین روش برای نشان دادن مکان نقشه های مرتبط با این دامنه در انتهای پرونده robots.txt است. در اینجا مثالی وجود دارد.
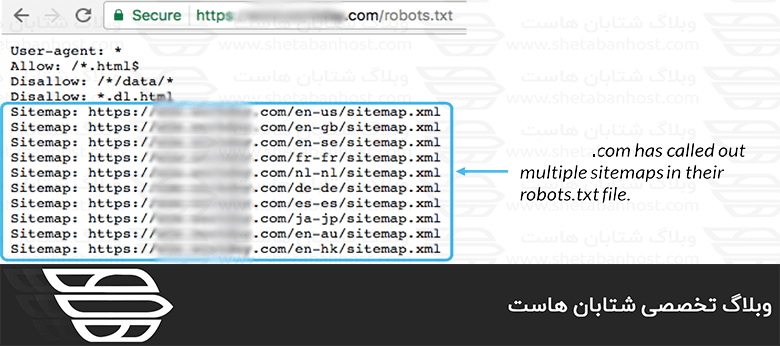
گرامر فنی robots.txt:
گرامر Robots.txt را می توان “زبان” فایل robots.txt دانست. پنج اصطلاح رایج وجود دارد که به احتمال زیاد در یک فایل ربات ها قرار دارد. آنها شامل موارد زیر هستند:
User-agent: خزنده اختصاصی وب که به شما دستورالعمل های خزیدن (معمولاً موتور جستجو) می دهد. لیستی از اکثر نمایندگان کاربر را می توان در اینجا یافت.
Disallow: دستورالعمل مورد استفاده برای گفتن به یک user-agent برای خزیدن URL خاص. فقط برای هر URL یک خط “Disallow” مجاز است.
مجاز (فقط برای Googlebot قابل اجرا است): دستور برای اطلاع به Googlebot می تواند به یک صفحه یا زیر پوشه دسترسی پیدا کند حتی اگر صفحه اصلی یا زیر پوشه آن مجاز نیست.
تاخیر در Crawl: چند ثانیه باید یک Crawl منتظر بارگیری و خزیدن محتوای صفحه باشد. توجه داشته باشید که Googlebot این دستور را تأیید نمی کند، اما سرعت خزیدن را می توان در کنسول جستجوی Google تنظیم کرد.
Sitemap: برای تماس با موقعیت مکانی هر نقشه سایت XML (های) مرتبط با این URL استفاده می شود. توجه داشته باشید که این دستور فقط توسطGoogle ، Ask ، Bing و Yahoo پشتیبانی می شود.
تطبیق الگو:
هنگامی که می خواهید URL های واقعی را مسدود یا مجاز کنید، فایل های robots.txt می توانند کاملاً پیچیده شوند زیرا به آنها اجازه می دهد تا از الگوی تطبیق برای پوشش طیف وسیعی از گزینه های ممکن URL استفاده کنند. Google و Bing هر دو از دو عبارت معمولی که برای شناسایی صفحات یا زیر پوشه هایی که یک SEO می خواهد استفاده شود، احترام می گذارند. این دو شخصیت ستاره (*) و علامت دلار ($) هستند.
- * یک کارت ویزیت است که نشان دهنده هر دنباله ای از شخصیت ها است.
- $ با پایان URL مطابقت دارد.
فایل Robot.txt در کجا ذخیره می شود:
هر زمان که به یک سایت مراجعه می کنید، موتورهای جستجو و سایر ربات های Crawl وب (مانند Crawl فیس بوک ، Facebot) می دانند و به دنبال فایل robots.txt هستند. اما، آنها فقط در یک مکان خاص به جستجوی آن فایل می پردازند: فهرست اصلی (به طور معمول دامنه یا صفحه اصلی شما). اگر یک نماینده کاربر به آدرس www.example.com/robots.txt مراجعه کند و فایل ربات ها را در آنجا پیدا نکند، فرض خواهد کرد که سایت فایل را ندارد و با خزیدن همه چیز در صفحه (و شاید حتی در کل سایت) ادامه یابد. حتی اگر صفحه robots.txt وجود داشته باشد، به عنوان مثال، .com/index/robots.txt یا www.example.com/homepage/robots.txt وجود داشته باشد ، توسط user agents کشف نمی شود و بنابراین سایت در دست تعمیر قرار می گیرد. انگار اصلاً فایل ربات ندارد.
برای اطمینان از یافتن فایل robots.txt، همیشه آن را در فهرست اصلی یا دامنه اصلی خود قرار دهید.
چرا به robots.txt احتیاج دارید:
فایل های Robots.txt دسترسی خزنده را به مناطق خاصی از سایت شما کنترل می کنند. در حالی که اگر به طور تصادفی Googlebot را از خزیدن کل سایت خود محروم کنید ممکن است بسیار خطرناک باشد ، برخی مواقع وجود دارد که یک فایل robots.txt می تواند بسیار مفید باشد.
برخی از موارد استفاده متداول از Robot.txt شامل موارد زیر است:
- جلوگیری از نمایش محتوای تکراری در SERP (توجه داشته باشید که ربات های متا معمولاً انتخاب بهتری برای این کار هستند).
- بخش های کامل یک وب سایت را خصوصی نگه دارید (به عنوان مثال ، سایت اصلی تیم مهندسی شما).
- نگه داشتن صفحات نتایج جستجوی داخلی در SERP عمومی.
- مشخص کردن نقشه سایت.
- جلوگیری از ایندکس کردن فایل های خاص در وب سایت خود از موتورهای جستجو (تصاویر ، PDF و غیره).
- به منظور جلوگیری از بارگیری بیش از حد سرورهای شما هنگام خزنده ها ، بارها و بارها چندین مقاله را به طور همزمان بارگیری کنید.
اگر در سایت شما هیچ زمینه ای وجود ندارد که می خواهید دسترسی user-agent را کنترل کنید، ممکن است به هیچ وجه به فایل robots.txt احتیاج نداشته باشید.
بررسی فایل robots.txt:
مطمئن نیستید که پرونده robots.txt دارید؟ به سادگی دامنه اصلی خود را تایپ کنید، سپس انتهای /URL /robots.txt را اضافه کنید.
اگر هیچ صفحه .txt ظاهر نمی شود، در حال حاضر صفحه (زنده) robots.txt ندارید.
بهترین شیوه ها برای SEO :
- اطمینان حاصل کنید که هیچ محتوا یا بخش هایی از وب سایت مورد نظر خود را نمی توانید مسدود کنید.
- پیوندها به صفحات مسدود شده توسط robots.txt دنبال نمی شوند. این بدان معناست که 1.) مگر در مواردی که از سایر صفحات قابل دسترسی در موتور جستجو (به عنوان مثال صفحات مسدود شده از طریق ربات ها نیست .txt، ربات های متا یا موارد دیگر)، منابع مرتبط خزیده نخواهند شد و ممکن است ایندکس نشوند. 2.) هیچ حقوقی برای پیوند از صفحه مسدود شده به مقصد منتقل نمی شود. اگر صفحاتی دارید که می خواهید حقوق صاحبان سهام منتقل شود، به غیر از robots.txt از مکانیزم مسدود کردن متفاوت استفاده کنید.
- از robots.txt برای جلوگیری از نمایش داده های حساس (مانند اطلاعات کاربر خصوصی) در نتایج SERP استفاده نکنید. از آنجا که صفحات دیگر ممکن است به طور مستقیم به صفحه حاوی اطلاعات شخصی پیوند برقرار کنند (بنابراین با دور زدن دستورالعمل های robots.txt در دامنه اصلی یا صفحه اصلی خود) ، ممکن است همچنان ایندکس شود. اگر می خواهید صفحه خود را از نتایج جستجو مسدود کنید، از روشی متفاوت مانند محافظت از رمز عبور یا دستورالعمل meta noindex استفاده کنید.
- برخی موتورهای جستجو دارای چندین user-agents هستند. به عنوان مثال، Google از Googlebot برای جستجوی ارگانیک و Googlebot-Image برای جستجوی تصویر استفاده می کند. بیشتر نمایندگان کاربر از همان موتور جستجو همان قوانین را رعایت می کنند، بنابراین نیازی به تعیین دستورالعمل برای هر یک از خزنده های متعدد موتور جستجو نیست، اما داشتن توانایی انجام این کار به شما امکان می دهد چگونگی خزیدن محتوای سایت را تنظیم کنید.
-
یک موتور جستجو محتویات robots.txt را ذخیره می کند ، اما معمولاً حداقل یک بار در روز محتوای ذخیره شده را به روز می کند. اگر پرونده را تغییر داده و می خواهید سریعتر از آنچه اتفاق می افتد ، آن را به روز کنید ، می توانید آدرس robots.txt خود را به Google ارسال کنید.
Robots.txt vs meta robots vs x-robots:
تفاوت بین این سه نوع دستورالعمل ربات چیست؟ اول از همه، robots.txt یک فایل متنی واقعی است، در حالی که ربات های متا و ایکس رهنمودهای متا هستند. فراتر از آنچه در واقع هستند، این سه ربات عملکردهای مختلفی دارند. Robots.txt رفتارهای خزنده سایت یا دایرکتوری را دیکته می کند، در حالی که روبات های متا و x می توانند رفتار نمایه سازی را در سطح صفحه (یا عنصر صفحه) دیکته کنند.
امیدواریم از این مقاله بهره لازم را برده و برای شما مفید بوده باشد. نظرات خود را با ما به اشتراک بگذارید.
ما را در شتابان هاست دنبال کنید.